Building the Pipeline
From a single function to a hierarchical generation system — and why the most important decision was proving the loop before building the orchestra.
Architecture sourced from 41 research documents across three domains. Pipeline implementation validated through five increments, 759 tests, and three complete production runs including an 11,000-word story with full evaluation scores.
The first version of the pipeline was a single function: generate a passage, evaluate it, revise it, repeat. It ran in a terminal and produced something that sounded vaguely Victorian. That was Increment 0. Four increments later, it is a hierarchical generation pipeline with MCP tools, custom evaluation rubrics, a corpus study of nine MacDonald works, and a director review flow. The most important architectural decision was still the first one: prove the single-agent loop works before building the orchestra.
Every framework vendor says “start simple.” Almost nobody shows you what that actually looks like across weeks of incremental complexity. This piece is the architecture narrative — from research findings to running code, from a single function call to a pipeline that produces an 11,000-word story in George MacDonald’s voice. The decisions that shaped it, the framework that runs it, the tools it uses to ground itself against the source material, and the cost engineering that keeps it viable on a solo practitioner’s budget.
The Simplicity Imperative
Every source converged on one point: start with the simplest thing that works.
Anthropic’s “Building Effective Agents” guide says most agents need only a while loop and tool calls. Braintrust’s canonical agent architecture analysis arrives at the same conclusion from production data. PydanticAI’s entire design philosophy is built around what they call “zero magic” — no hidden abstractions, no framework opinions that obscure failure modes. One industry analysis found that 40% of multi-agent pilots fail within six months, and the dominant cause is over-engineering: teams build the orchestra before they have proven the first instrument plays in tune.
That last figure deserves the caveat: it comes from a single industry report, not from peer-reviewed research. I cannot tell you it is precise. I can tell you it matches the pattern visible across every framework’s documentation, every production post-mortem I read in the research phase, and every honest conversation about what goes wrong when agent systems move from demo to deployment. The failure mode is always the same. Someone builds a sophisticated multi-agent architecture because the architecture looks impressive, then discovers that the agents cannot reliably do the simple version of the task — and now they have coordination overhead, token multiplication, and debugging complexity layered on top of an unvalidated core.
So the rule was: a single-agent generate-evaluate-revise loop first. Prove the loop produces prose that moves toward MacDonald’s voice. Measure it with stylometric tools. Read the output. Only when a measured ceiling demands more complexity do you add it. This is not patience as virtue. It is engineering discipline backed by forty-one documents of convergent evidence.
Choosing the Framework
The framework decision was made before a single line of pipeline code was written, and it was validated from three independent angles.
Architectural fit. The Claude Agent SDK sits at what the framework landscape analysis calls Position 2 on the build-versus-buy spectrum: a minimal SDK that provides primitives without imposing opinions. Its built-in file access, code execution, and tool support map directly to what a creative pipeline needs — reading reference texts, writing drafts, running stylometric analysis. The alternatives were instructive. LangGraph offers a graph-based state machine that is powerful for complex workflows but adds abstraction opacity. CrewAI’s role-based metaphor is intuitive but its documented hierarchical process failures make it unsuitable for production creative work. The OpenAI Agents SDK provides first-class guardrail primitives that the Claude SDK lacks — a real gap — but the Claude SDK’s patterns-over-frameworks philosophy aligned with the simplicity imperative more cleanly than any alternative.
Ecosystem. Python dominates agent engineering: eight of the ten most-starred agent frameworks are Python-based, five major frameworks are Python-only. The Claude Agent SDK has full Python parity. This is not a cosmetic consideration. When something breaks at 2 AM during a pipeline run, you need the ecosystem — libraries, examples, debugging tools, community knowledge — that lets you diagnose and fix the problem without reverse-engineering framework internals.
Job market alignment. Agent engineering is a seniority-weighted discipline. The pipeline is not just a creative production system; it is a portfolio artifact that demonstrates orchestration expertise. The Claude Agent SDK is the framework that the cross-domain analysis identified as the best investment for both the pipeline and the builder’s professional positioning.
The guardrail gap is worth addressing directly. The OpenAI Agents SDK provides a dedicated Guardrail class with a tripwire mechanism for detecting prompt injection and content violations. The Claude Agent SDK has no equivalent. For a customer-facing agent processing untrusted input, this would be disqualifying. For a creative writing pipeline processing its own generated text — where the threat model is non-adversarial and the inputs are controlled — it is a gap that can be mitigated architecturally. The pipeline uses a HookMatcher permission guard that denies writes outside the output directory, and custom tools that never write files eliminate the need for broader file-system guardrails. The gap is real. For this project, it is manageable.
The Architecture
The pipeline implements hierarchical generation — the single most impactful coherence intervention in the literature, unanimously endorsed by five peer-reviewed systems: Dramatron (CHI 2023), DOC (ACL 2023), Re3 (EMNLP 2022), DOME (NAACL 2025), and StoryWriter (CIKM 2025). The principle is straightforward: decompose creative work into stages of increasing specificity, and evaluate at each stage before committing to the next. Do not ask a model to produce a complete story in a single pass. Plan first, then outline, then generate.
The pipeline’s flow looks like this:
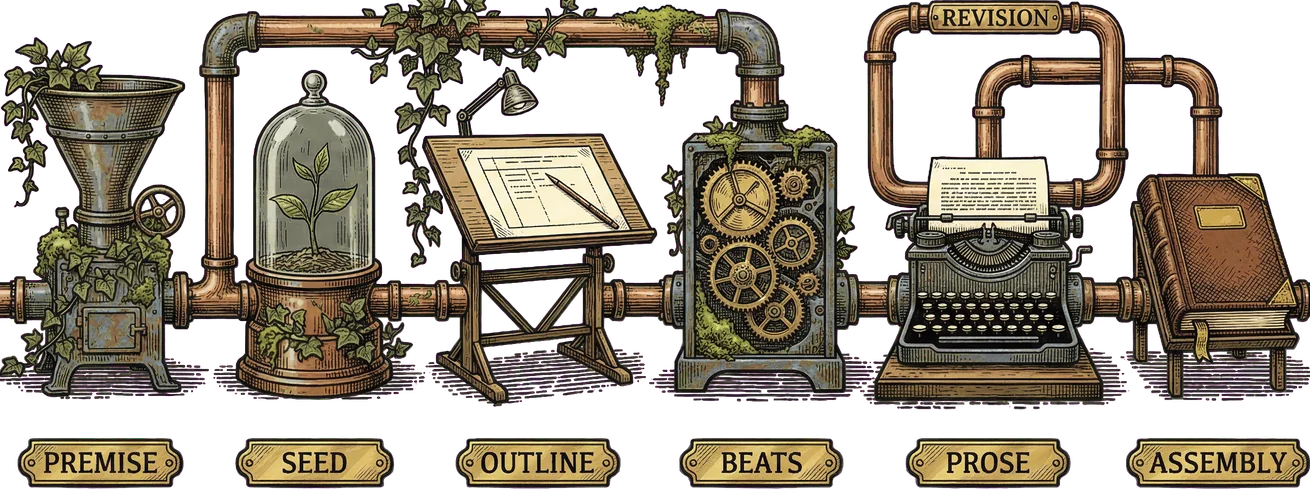
A Python orchestrator — runner.py — drives the entire process. It is not an LLM making routing decisions. It is deterministic Python code that calls agents in a fixed order with explicit inputs and outputs. This is deliberate. Hierarchical generation has a fixed execution order: premise, then seed, then outline, then beats, then per-beat prose, then assembly. LLM-driven delegation would add latency and non-determinism with no benefit. Every agent call is a typed Python function with known inputs and outputs, known cost characteristics, and Python stack traces when something fails. The agents do the creative work. Python does the plumbing.
The stages, in order:
Premise expansion. A story premise — a seed idea, a thematic direction, a MacDonald-universe setting — is expanded into a full story seed. The planner agent takes the premise, the voice specification, and the lore bible as context, and produces a structured seed: characters, setting, thematic arc, central MacDonald-like question. This is a stateless call using the Agent SDK’s query() function with ClaudeAgentOptions specifying the planner configuration, output schema, and MCP tool access.
Seed review. A director review gate. The human reads the seed, approves it, steers it, or rejects it. This is not a rubber stamp. The seed establishes everything that follows — the faithfulness hierarchy means worldview and narrative logic matter more than any surface feature, and those dimensions are set here. The director’s input at this stage has more impact per minute of attention than at any other point in the pipeline.
Outline generation. The approved seed becomes an outline — a structured document specifying scenes, their function in the narrative arc, transitions between them, and the MacDonald scene types each embodies (encounter, landscape, recognition, threshold). The planner agent generates this with structured output enforced via ClaudeAgentOptions.output_format — the Agent SDK’s JSON schema enforcement ensures the outline conforms to the expected structure. The outline is evaluated by a dedicated outline evaluator against a four-dimension structural rubric.
Beat generation. The outline becomes a sequence of beats — the most granular planning unit before prose. Each beat specifies what happens, what it accomplishes in the narrative, what MacDonald voice dimensions are most relevant, and what the emotional trajectory is across the beat. A dedicated beat evaluator assesses the sequence against a five-dimension rubric. Both the outline and beat stages have access to the persistent MCP tools — corpus lookup and lore bible lookup — so the planner can ground its structural decisions in MacDonald’s actual works.
Per-beat prose generation. This is where the writing happens. For each beat, the pipeline enters a revision loop. A writer agent generates prose for the beat, informed by the voice specification, the beat description, preceding passages for continuity, and the broader story context. An evaluator agent scores the passage against the six-dimension faithfulness rubric — the rubric weighted by the faithfulness hierarchy, so worldview scores count six times as heavily as surface feature scores. If the passage falls below the quality threshold, the writer revises it, informed by the evaluator’s specific feedback.
The revision loop uses ClaudeSDKClient — the Agent SDK’s multi-turn session support — to maintain conversation context across successive drafts. The writer does not start from scratch on each revision. It carries the conversation forward, seeing its previous attempt, the evaluator’s critique, and the specific dimensions that need improvement. This is a meaningful architectural choice: stateless query() calls for single-shot agents (planner, evaluators), multi-turn ClaudeSDKClient sessions for the writer’s iterative revision process.
Story assembly. The per-beat passages are assembled into a complete story. Transition checks and continuity verification run at the seams. A full-story evaluator assesses the assembled narrative against a nine-dimension rubric — the six prose dimensions plus three story-level dimensions: narrative arc coherence, thematic integration, and worldview consistency across the full text.
The result is a complete story with evaluation scores at every level of granularity — beat-level, passage-level, and story-level — plus a cost report, a full event log, and every intermediate artifact saved to a timestamped output directory.
The Artifact Pattern
Multi-agent systems consume approximately fifteen times more tokens than single-turn chat interactions, with 53-86% token duplication rates documented across major frameworks. Those numbers come from Anthropic’s own engineering blog and from production measurements across the framework landscape. The duplication happens because agents pass context to each other, and without careful management, the same voice specification, the same evaluation rubric, the same story outline gets copied into every agent’s context window at every turn.
The artifact pattern is the mitigation: store drafts, outlines, style guides, and evaluation results externally. Pass structured metadata and lightweight references through handoffs. Do not stuff the full voice specification into every agent call. Instead, make it available as a tool the agent can query when it needs specific guidance.
In practice, this means the pipeline stores every intermediate artifact — story seeds, outlines, beat sequences, passages, evaluation results — as structured files in a timestamped output directory. The orchestrator passes references and summaries, not full documents. When the writer needs to check MacDonald’s sentence-length profile, it calls the stylometric_check tool. When it needs to verify a lore-bible detail about MacDonald’s use of light imagery, it calls lore_bible_lookup. The information enters the context window on demand, scoped to what the agent actually needs for the current task, rather than being pasted wholesale into every prompt.
This is not an optimization afterthought. It is a first-order architectural decision that makes the difference between a pipeline that costs two dollars per story and one that costs fifty.
The Tools
The pipeline uses five custom MCP tools, organized into two servers: a persistent server available to all agents throughout the pipeline, and a per-beat server rebuilt for each revision loop iteration.
The persistent server — golden-key-tools — carries three tools:
corpus_lookup searches MacDonald’s corpus by work, chapter, or keyword. The pipeline’s corpus study acquired nine MacDonald fantasy works from Project Gutenberg — over 408,000 words — and chunked them at the chapter level with structured metadata. When a writer agent needs to check how MacDonald handles a garden scene, or how he introduces a supernatural element, it calls corpus_lookup with a keyword and gets matching text chunks with source metadata. Results are truncated to 2,000 characters per chunk to manage context window usage. The tool is a scalpel, not a firehose — it gives the agent precisely the reference material it needs without flooding the context.
stylometric_check profiles a passage against the MacDonald corpus baseline. It returns sentence length statistics, Moving Average Type-Token Ratio, hapax ratio, Burrows’ Delta distance, and per-metric divergence flags. This is the external grounding that Kamoi et al. (TACL 2024) and Huang et al. (ICLR 2024) established as non-negotiable: self-correction without external feedback is unreliable, and stylometric comparison against the source corpus provides computational ground truth that the revision loop can act on. When the evaluator flags a passage as drifting from MacDonald’s voice, the writer can call stylometric_check and see exactly which measurable dimensions have diverged.
lore_bible_lookup queries the MacDonald lore bible by faithfulness hierarchy dimension. The lore bible is the pipeline’s most comprehensive reference artifact — assembled from the three-tier corpus study, organized by the six dimensions of the faithfulness hierarchy (worldview, narrative logic, thematic consistency, emotional register, voice, surface features). Each dimension includes patterns extracted from the corpus, validated examples, and agent guidance. When the writer needs to ground a passage in MacDonald’s worldview — grace as ambient condition rather than interventional reward — it calls lore_bible_lookup with dimension="worldview" and gets the specific patterns and examples that should shape the prose.
The per-beat server — golden-key-revision — carries two tools that are rebuilt for each beat’s revision loop:
score_history returns the score trajectory across revision iterations — composite and per-dimension scores for each draft. The writer can see whether its revisions are improving, plateauing, or degrading, and which specific dimensions are moving. This closes the feedback loop: the writer does not revise blindly. It revises with full visibility into what the evaluator scored and how the scores have changed.
revision_context returns the evaluator’s specific feedback, gap-weighted priority dimensions (calculated as weight times the gap between the maximum score and the current score), and any stylometric flags from the current loop state. This tells the writer not just “revise” but “revise specifically toward these dimensions, in this priority order.”
All five tools are declared with the Agent SDK’s @tool decorator and registered via create_sdk_mcp_server. The tool architecture reflects the Model Context Protocol’s design: tools are interoperable, discoverable, and scoped. The persistent server is shared across all agent roles. The revision server is rebuilt per-beat because its state — score history, evaluator feedback — is specific to the current revision loop.
Cost Engineering
Cost is not a second-order concern. The fifteen-times token multiplication documented in multi-agent systems means that a naive implementation of this pipeline — full context in every call, no caching, no artifact pattern — would cost an order of magnitude more than the engineered version.
Prompt caching is the primary mitigation. Anthropic offers a 90% discount on cached reads — verified vendor documentation, subject to change, but transformative at the current price point. The voice specification, the evaluation rubrics, the lore bible sections that agents query repeatedly — these are stable content that changes only between pipeline runs, not between agent calls within a run. By structuring prompts so that stable content sits in cacheable prefixes, the pipeline pays full price once and 10% on every subsequent call that uses the same prefix.
This reshapes the architectural decision about what goes into the context window. The traditional retrieval-augmented approach says: keep the context lean, retrieve what you need on demand. Prompt caching inverts that calculus for stable content. It is now cheaper to include the full voice specification in a cached prefix than to retrieve excerpts on demand — because the cached inclusion costs 10% of the token price, while dynamic retrieval requires a tool call, a search, and then the retrieved content enters the context at full price. The pipeline’s context engineering treats stable reference material (voice spec, rubrics, lore bible) as cached-stable content positioned at prompt boundaries, and beat-specific material (the current beat description, preceding passages, evaluator feedback) as dynamic content assembled per call.
Cost tracking is per-stage and per-role. The pipeline’s CostTracker records every API call with its cost, agent role, and pipeline stage. This is not the Agent SDK’s built-in max_budget_usd — that enforces a per-call ceiling, which is too coarse for a pipeline with dozens of calls across multiple stages. Manual tracking provides the breakdown needed for optimization: which stage consumes the most budget, which agent role is the most expensive, where token duplication is highest. The analytical cost estimates from the implementation strategy analysis suggested $2-15 per story. Those are projections, not measurements from this pipeline’s actual runs — the real numbers come from the cost tracker and the timestamped run artifacts.
The Phased Build
The pipeline was not designed on a whiteboard and built to spec. It was grown through five increments, each justified by what the previous increment revealed.
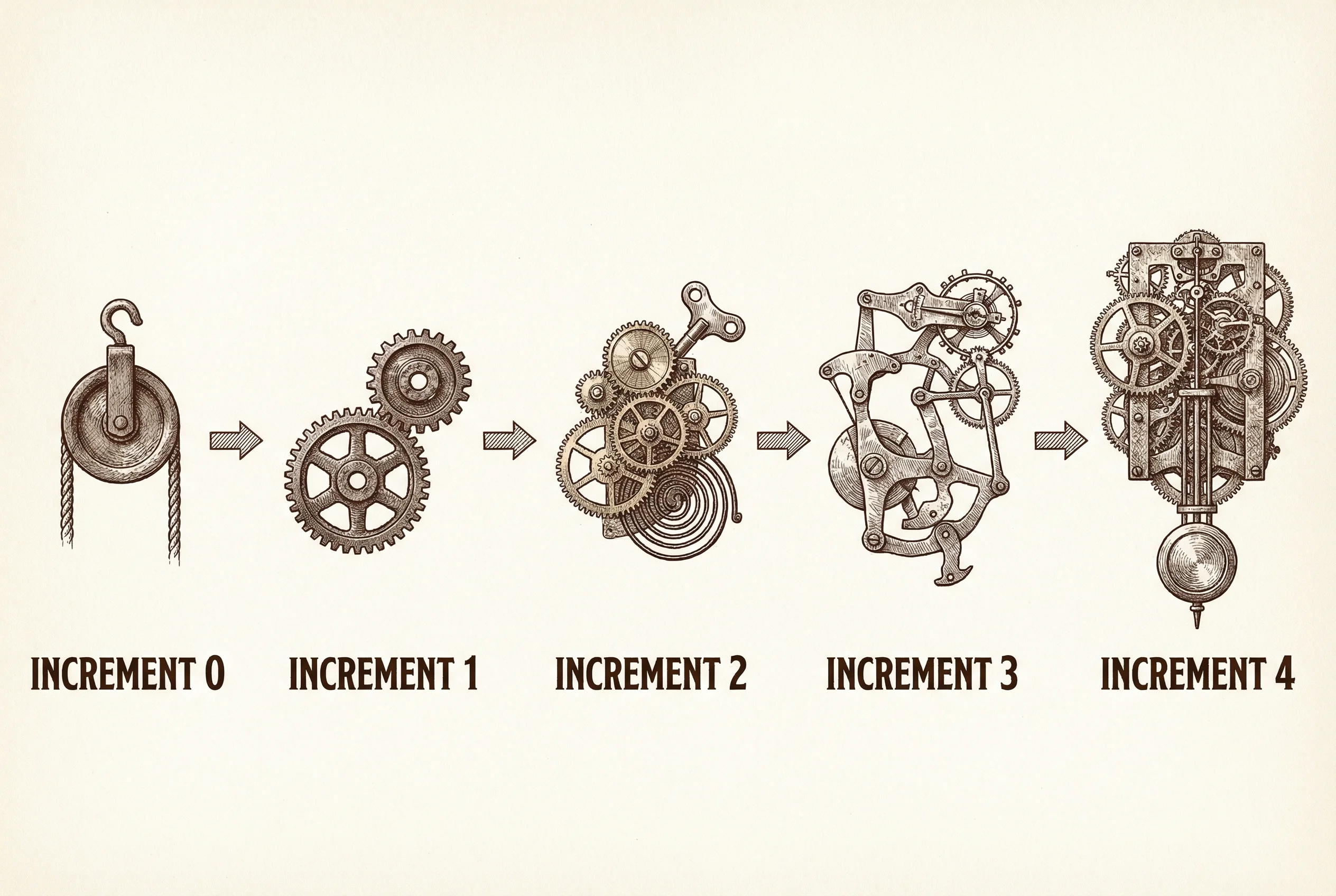
Increment 0: Generate and Evaluate. A single function that calls Claude with a MacDonald voice prompt, generates a passage, and evaluates it against a basic rubric. Rich terminal UI with themed panels and score bars. This was the proof of concept: can the model produce anything that sounds remotely Victorian? Can an evaluator provide structured feedback? The answer to both was yes, with heavy caveats. The prose sounded generically archaic. The evaluator could identify surface-level conformance but had no ground truth to assess depth.
Increment 1: The Revision Loop. Generate, evaluate, revise, re-evaluate. The core loop that the simplicity imperative demanded as the first validation. The revision loop introduced ClaudeSDKClient for multi-turn writer sessions — the writer sees its previous draft, the evaluator’s critique, and the specific dimensions flagged for improvement. This increment demonstrated that iterative revision improves scores. It also demonstrated the ceiling: without external grounding, the writer converges toward a statistical center. The prose got more consistent. It did not get more MacDonald.
Increment 2: Corpus Study and Voice Extraction. The pipeline needed ground truth. No published stylometric analysis of MacDonald existed, so the pipeline built one. Nine MacDonald fantasy works acquired from Project Gutenberg — 408,000 words — chunked at the chapter level, profiled mechanically (Tier 1: sentence length, vocabulary diversity, function word ratios, punctuation patterns), enriched by agent extraction (Tier 2: imagery systems, thematic preoccupations, narrative stance, paragraph rhythm), and anchored by human-curated reference passages (Tier 3). The voice specification and lore bible emerged from this study. They became the pipeline’s most referenced artifacts.
Increment 3: Stylometric Grounding and External Feedback. The corpus study gave the pipeline a baseline. This increment built the tools to use it. The stylometric_check tool profiles each passage against the MacDonald baseline. The corpus_lookup tool gives the writer access to MacDonald’s actual prose as reference material. The lore_bible_lookup tool makes the faithfulness hierarchy operational — the writer can query specific dimensions and get patterns, examples, and guidance drawn from the corpus study. This was the increment where the self-correction finding became tangible: the revision loop with grounded tools produced measurably different output than the ungrounded loop. The prose began to sound less like “generic Victorian” and more like something with MacDonald’s specific texture — the intrusive narrator, the light-and-shadow imagery, the theological weight carried in narrative logic rather than stated as doctrine.
Tech debt pause: Reusable revision loop. Between increments, the revision loop was refactored into a reusable module with per-stage configuration injection. This sounds mundane. It was architecturally significant. The same revision loop pattern — generate, evaluate, revise with feedback — applies at multiple stages (per-beat prose, outline refinement, beat sequence refinement). Building it once and configuring it per stage eliminated the duplication that would have accumulated as the pipeline grew.
Increment 4: Hierarchical Generation. The full pipeline. Premise expansion, seed generation with director review, outline generation with structural evaluation, beat generation with sequence evaluation, per-beat prose generation with the grounded revision loop, story assembly with transition checks and full-story evaluation. Eight features in total, each building on the infrastructure from previous increments. Director review gates at outline, beat, and story stages. A hierarchical stage indicator in the terminal UI so the operator can see where the pipeline is in the generation flow.
This was the largest increment, and it was justified by what Increment 3 revealed: per-passage quality had improved significantly with grounded tools, but the assembled story lacked structural coherence. Passages were individually faithful to MacDonald’s voice but did not build toward a narrative arc. Five peer-reviewed systems had predicted this — Dramatron, DOC, Re3, DOME, and StoryWriter all endorse hierarchical generation precisely because passage-level quality does not guarantee story-level quality. The outline and beat stages provide the structural scaffolding that individual passages hang on.
The SDK Migration
The pipeline was originally built with raw Anthropic API calls. The migration to the Claude Agent SDK was driven by three concrete gains, not by framework enthusiasm.
MCP tool support. The custom tools — corpus lookup, stylometric check, lore bible lookup, score history, revision context — needed a server infrastructure. Building a custom MCP server from scratch is possible. Using the Agent SDK’s @tool decorator and create_sdk_mcp_server reduced that work to declaring the tool functions and registering them. The persistent and per-beat server architecture fell out naturally from the SDK’s design.
Multi-turn conversation state. The revision loop requires the writer to see its previous draft, the evaluator’s feedback, and revision guidance across multiple turns. ClaudeSDKClient provides this natively. The pre-SDK version managed conversation history manually, passing the full message array on each call. ClaudeSDKClient handles the state, including prompt caching on the stable prefix.
Structured output. Evaluators and planners produce structured data — scores, dimensions, outlines, beat sequences. ClaudeAgentOptions.output_format with JSON schema enforcement ensures the output conforms to the expected structure. Before the migration, the pipeline parsed free-text output with regex patterns and hope. Schema enforcement eliminated an entire category of parsing failures.
What was not used is as instructive as what was.
AgentDefinition and subagent delegation — unused. The pipeline does not use LLM-driven routing between agents. Each agent role is a typed Python function called by the orchestrator in a deterministic order. One industry analysis found that 40% of multi-agent pilots fail from over-engineering. Subagent delegation adds non-determinism and latency with no benefit when the execution order is fixed. If measured output quality eventually plateaus and cannot be improved by other means, subagent delegation remains an option for a future increment. It was not needed.
max_budget_usd — unused. The SDK can terminate an agent call that exceeds a cost ceiling, but it operates per-call. The pipeline’s cost tracking needs are per-stage and per-role, accumulated across many calls into a single report. CostTracker records cost by agent role and pipeline stage. ResultMessage cost data feeds the tracker regardless, so budget exhaustion is handled cleanly if it ever occurs.
Built-in permission tools (Read, Write, Glob, Bash) — unused. The SDK provides general-purpose file access tools that agents can invoke autonomously. The pipeline does not enable these. The three persistent MCP tools and two revision tools cover everything pipeline agents need. Enabling general file access would expand the attack surface without adding capability. The HookMatcher permission guard denies writes outside the output directory as a safety net, but the custom tool design makes even that guard mostly redundant — tools that never write files do not need write permission.
The migration philosophy was explicit: adopt what provides measurable improvement over existing infrastructure. Leave the rest. The Agent SDK is not a destination. It is a tool belt, and you take the tools you need.
What the Architecture Looks Like
The system is best understood as three layers working together.
At the top, a Python orchestrator drives the pipeline through its stages: premise expansion, seed review, outline generation, beat generation, per-beat prose with revision loops, and story assembly. This is deterministic code — no LLM routing, no dynamic agent creation. It calls agents the way a build system calls compilers: in a known order, with known inputs, expecting structured outputs.
In the middle, agent calls. Stateless query() calls for single-shot work — the planner expanding a premise, the evaluator scoring a passage, the study extractors analyzing corpus chunks. Multi-turn ClaudeSDKClient sessions for the writer’s revision loop, where conversation context across successive drafts matters. Each agent role has its own ClaudeAgentOptions configuration specifying the model, system prompt, turn limits, MCP server access, output format, and hooks.
At the bottom, MCP tools provide the external grounding. The persistent golden-key-tools server carries corpus lookup, stylometric check, and lore bible lookup — the three tools that connect the generation process to MacDonald’s actual voice. The per-beat golden-key-revision server carries score history and revision context — the tools that close the feedback loop within each revision iteration. Both servers are assembled via create_sdk_mcp_server from @tool-decorated Python functions. The tools are typed, documented, and scoped. The writer agent can search the corpus. It cannot delete the corpus.
Three tiers of turn limits enforce cost discipline. Tool-using agents (writer, planner) get thirty turns — enough for multiple tool calls and iterative reasoning. Evaluators get five turns — enough to assess and score, not enough to wander. Study extractors get one turn — single-pass analysis, no tool use, no revision.
Event logging captures every agent call, tool invocation, evaluation score, and cost record as structured JSON lines. Every intermediate artifact — seeds, outlines, beat sequences, passages, evaluation results — is saved to the timestamped run directory. The pipeline is fully auditable. You can reconstruct exactly what happened at every stage of any run, which matters for a project whose entire purpose is demonstrating process transparency.
What This Demonstrates
The pipeline is a portfolio artifact as much as it is a production system. The engineering decisions are the content. The simplicity imperative, backed by convergent evidence across twenty framework landscape documents, says: resist the pull of impressive architecture and build only what you can prove you need. The hierarchical generation pattern, validated by five peer-reviewed systems, says: decompose creative work into stages of increasing specificity and evaluate at each stage. The artifact pattern, driven by the fifteen-times token multiplication problem, says: store externally, pass references, pay for tokens once. The external feedback principle, established by peer-reviewed research on self-correction failure, says: ground your revision loop in something outside the model’s own judgment.
Every one of these principles translated into a specific architectural choice. The single-agent loop before the orchestra. Python orchestration over LLM routing. Custom MCP tools over general file access. Prompt caching as context engineering strategy. Per-stage cost tracking. Phased increments justified by measured need.
The pipeline ran three complete production runs. The third produced “The Walled Garden” — an 11,000-word story with evaluation scores at every level of granularity. Whether those scores mean the story is faithful to MacDonald is a question the evaluation architecture article addresses. Whether the story feels alive is a question only the reader can answer. But the pipeline itself — the architecture, the decisions, the incremental build from a single function to a full hierarchical generation system — demonstrates what it was designed to demonstrate: that a solo practitioner with research discipline and engineering rigor can build a production agent system that does real work, not just impressive demos.
The builder’s limitation is the same as the pipeline’s limitation: it was designed, built, and evaluated by the same person. Whether that matters is addressed elsewhere in this collection. Here, at the bench, the focus is on what was built and why. The joints are visible. The tools are on the table. The reader who builds systems can examine the work and judge the craft.